In this tutorial, we will learn about Bag of Words (BOWs), how BOWs is used as a feature extractor, then build a classifier using the features extracted.
In order to model a text documents, the raw text cannot be fed directly to the algorithm as these algorithms expect numerical feature vectors so instead we need to turn the text content into numerical feature vectors.
From the scikit-learn documentation: We call vectorization the general process of turning a collection of text documents into numerical feature vectors.
When modelling a data it is important to decide what features of the input are relevant, and how to encode those features. When we consider a textual data such as a sentence or a document for instance the observable features are the counts and the order of the letters and the words within the text and as such we a way to extract these features from the text. There are several ways of extracting features from a textual data but in this tutorial we will only consider a very common feature extraction procedures for sentences and documents known as the bag-of-words approach (BOW) which looks at the histogram of the unique words within the text ( considering each word count as a feature.)
Bag Of Words (BOWs) Approach
Is a feature extraction technique used for extracting features from textual data and is commonly used in problems such as language modeling and document classification. A bag-of-words is a representation of textual data, describing the occurrence of words within a sentence or document, disregarding grammar and the order of words.
How does Bag of Words Works
In order to understand how bag of words works let consider the two simple text documents:
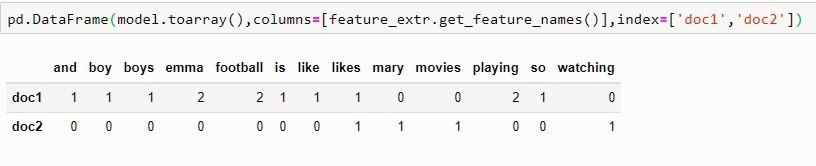
1. Boys like playing football and Emma is a boy so Emma likes playing football
2 Mary likes watching movies
Based on these two text documents, a list of token (words) for each document is as follows
['Boys', 'like', 'playing', 'football', 'and', 'Emma', 'is' 'a', 'boy', 'so', 'Emma',
'likes', 'playing', 'football']
['Mary', 'likes', 'watching', 'movies']
denoting document 1 by doc1 and 2 by doc2, we will construct a dictionary (key->value pair) of words for both doc1 and doc2 where each key is a word, and each value is the number of occurrences of that word in the given text document.
doc1={ 'a' : 1, 'and' : 1, 'boy' : 1, 'Boys' : 1, 'Emma' : 2, 'football' : 2,
'is' : 1, 'like' : 1, 'likes' : 1, 'playing' : 2, 'so' : 1}
dco2={'likes' : 1, 'Mary' : 1, 'movies' : 1 ,'watching' : 1}
NOTE : the order of the words is not important
considering a as a stop word, we first define our vocabulary words, which is the set of all unique words found in our document set and it consist of
and, boy, boys, emma, football, is, like, likes, mary, movies, playing, so, watching
and the features extracted using bag of words for the document set will be

scikit-learn CountVectorize implementation
Using CountVectorize the text is preprocessed, tokenize and stopwords are filtered, it then builds a dictionary of features and transforms documents to feature vectors:
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
docs=['Boys like playing football and Emma is a boy so Emma likes playing football',
"Mary likes watching movies"]
feature_extr=CountVectorizer()
model=feature_extr.fit_transform(docs)
Disadvantages
Although BOWs is very simple to understand and implement, it has some disadvantages which include
- highly sparse vectors or matrix as the are very few non-zero elements in dimensions corresponding to words that occur in the sentence.
- Bag of words representation leads to a high dimensional feature vector as the total dimension is the vocabulary size.
- Bag of words representation does not consider the semantic relation between words by assuming that the words are independent of each other.
Buiding a Classifier with the features extracted using BOWS
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.linear_model import SGDClassifier
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
The dataset called “Twenty Newsgroups”. which is a collection of approximately 20,000 newsgroup documents, partitioned (nearly) evenly across 20 different newsgroups. Official description of theTwenty Newsgroups data will be used as our data but instead of the 20 different groups we will work on a partial dataset with only 11 categories out of the 20 available in the dataset. The code below is list of the 11 categories.
categories = ['alt.atheism', 'soc.religion.christian','comp.graphics', 'sci.med','sci.electronics',
'sci.space','talk.politics.guns','talk.politics.mideast','talk.politics.misc',
'talk.religion.misc','misc.forsale']
Loading the training data
twenty_news_train=fetch_20newsgroups(subset='train',categories=categories,remove=('footers','headers','quotes'))
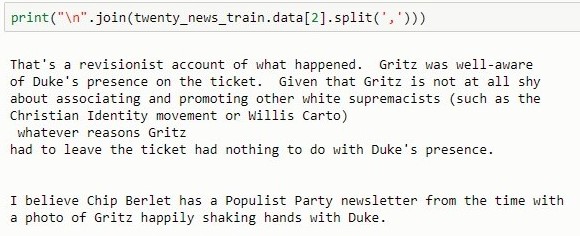
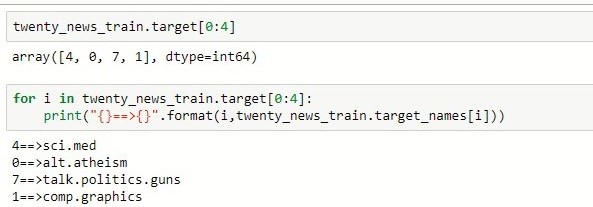
Let’s print the third lines of the first loaded file and the first four categories with the target variable :
A Classifier Pipeline
In order to make the vectorizer => classifier easier to work with, let build a pipeline with a regularized linear models with stochastic gradient descent (SGD) learning as our classifier as below:
news_clf.fit(twenty_news_train.data,twenty_news_train.target)
Let now train the classifier
news_clf.fit(twenty_news_train.data,twenty_news_train.target)
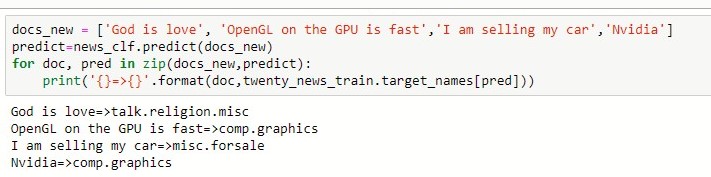
We now test the classifier on new instances
Evaluation of the performance on the test set
twenty_news_test=fetch_20newsgroups(subset='test',categories=categories,remove=('footers','headers','quotes'))

References: